開発
2016/6/1
SVM(サポートベクターマシン)
Rei Kumazawa
こんにちは、アルバイトの熊澤です。
自分は今、ガンマーカプロジェクトの統計の部分を担当させてもらっています。
この前のブログでメタアナリシスについて少し書きましたが、今回のプロジェクトではメタアナリシスを使うのは難しそう...
なので、解決案としてSVMを使ってみてはどうだろうかとなりましたので、それについて書いていきたいと思います。
SVMってなに?
自分はSVMという単語自体聞いたことがなかったのですが、みなさん知っていますか?
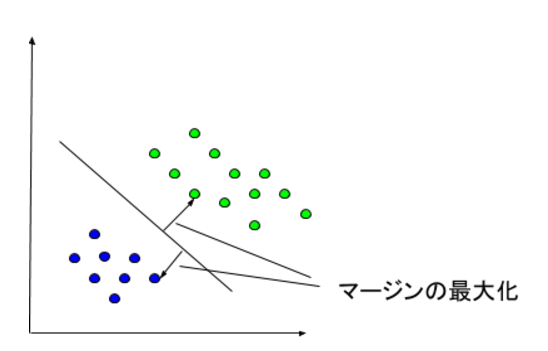
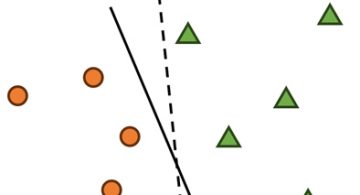
まず、SVMというのは、2つのクラスの識別面をマージンが最大になるようにする識別手法です。
少し触ってみる
問一だけやってみた!
問題はこちら
library(kernlab)
auth <- read.table("CodeIQ_auth.txt")
mycoins <- read.table("CodeIQ_mycoins.txt")
svm <- ksvm(V3 ~., data=auth)
result 0.5, 1, 0), "ans.txt", quote=F, col.names=F, row.names=F)
こちらのサイトで例題等が載っているので、みなさんやってみるといいかも!
まとめ
これってまんまガンマーカに使えるじゃないですか!!!!
まずはデモデータを作成してSVMに突っ込んでみようと思います。
ちゃんと分類できるといいなあ...
参考文献
http://www.sist.ac.jp/~kanakubo/research/neuro/supportvectormachine.html
- Tweet
-

 2024/01/05
2024/01/05 2023/08/18
2023/08/18 2023/07/14
2023/07/14 2023/05/12
2023/05/12 2023/04/21
2023/04/21 2023/04/19
2023/04/19 2023/03/24
2023/03/24 2022/12/23
2022/12/23