人工知能
An Introduction to Federated Learning
ZHUOTAO LIAN
Federated learning is quite a hot topic recently that many top conferences’ papers on federated learning have been published. Today I will briefly introduce federated learning, and point out the core challenges.
What is federated learning? And why?
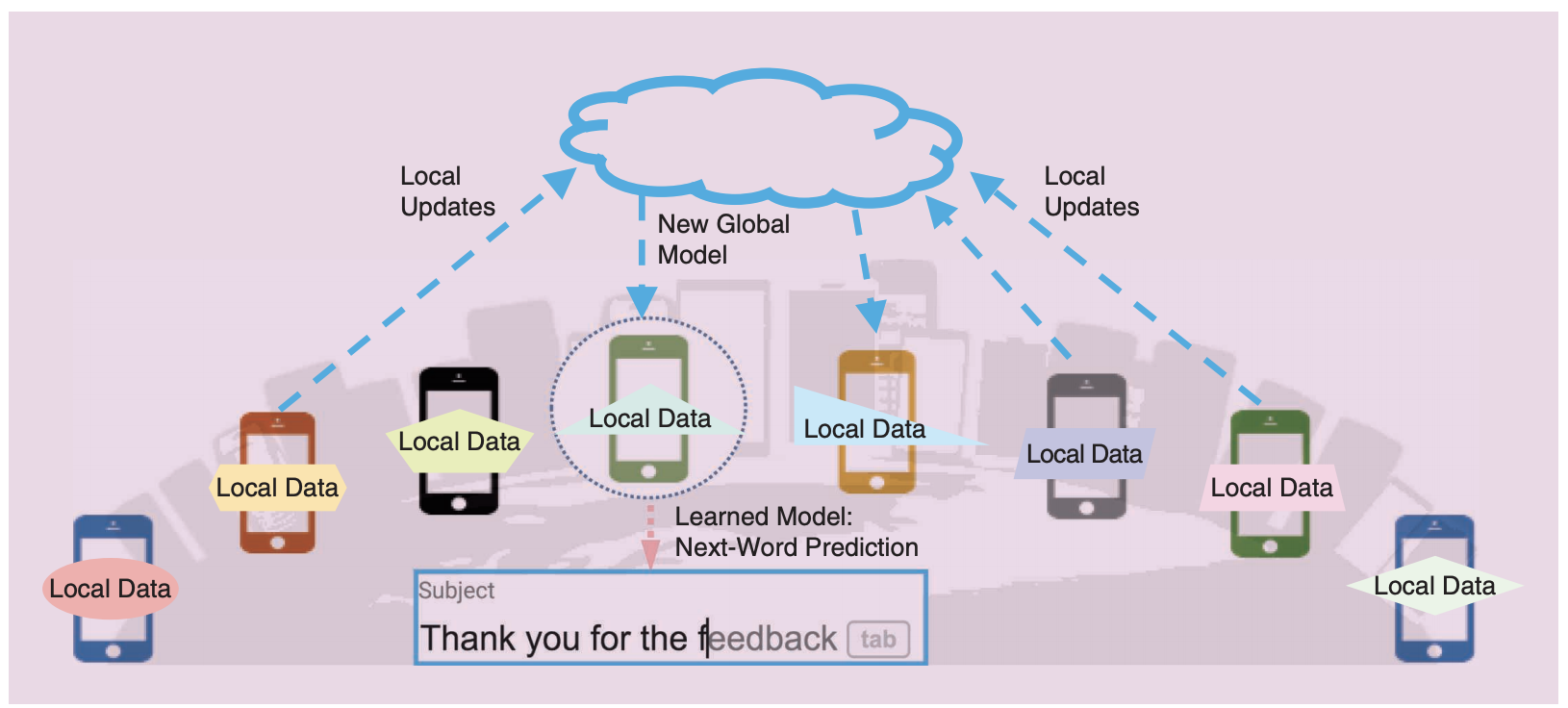
Federated Learning is a novel machine learning technique to train a high-quality global model while training data remains distributed over a large number of clients. The global model updates by gathering all the update information (parameters or gradients) from clients, each with unreliable and relatively slow network connections. As a result of that the update information includes no raw data, personal privacy could be protected.
As the figure shows, there is usually a central server that holds the global model. At the start of each training epoch, the global model will be sent to all clients to update their local models. After local training on mobile devices, the training results will be sent to the global server. And then the server performs weighted average of them to update the global model.
Next question is why we use federated learning? In fact I have mentioned it before. That’s mainly because in most industries, data exists in the form of isolated islands. The other is the strengthening of data privacy and security. Federated learning could train a global model without gathering all the raw data. So it was introduced by Google in 2016 as a novel machine learning technique.
Core challenges in Federated Learning
1. Expensive Communication Cost
Communication is a bottleneck in federated learning. That’s because the federated networks are comprised of a massive number of mobile devices. And when all devices send the training results which could have a large size to the central server, the bottleneck could appear. Also, the mobile network is usually unstable, and the communication could be slower than training locally. To deal with this challenge, it’s necessary to develop communication-efficient methods. There are mainly two directions. The first one is to reduce the data size of transmitted messages. And the other one is to reduce the number of communication rounds, such as sending training results after training several rounds locally. Also some researches focus on combining edge computing with federated learning to reduce communication cost.
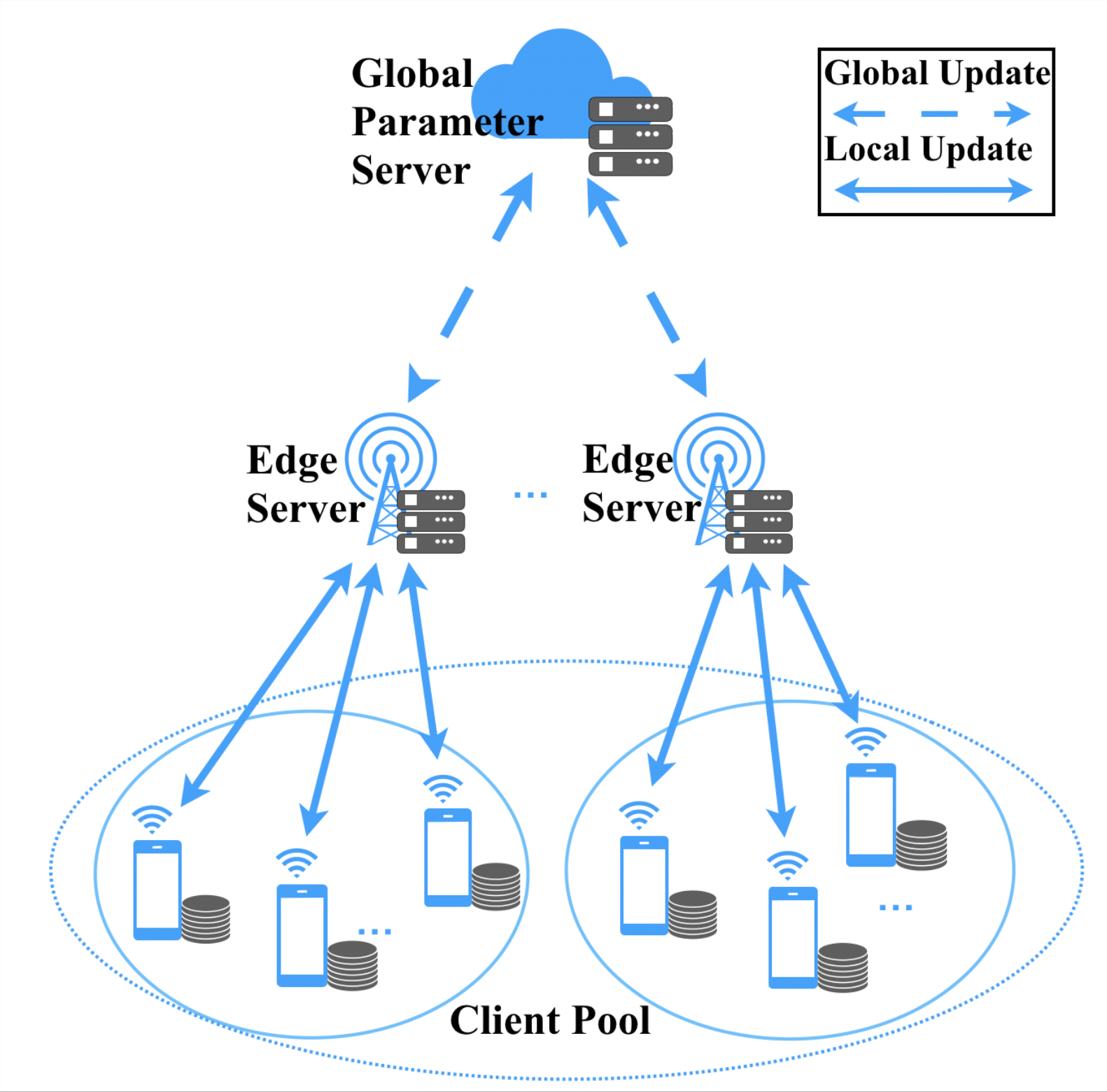
2. System Heterogeneity
System heterogeneity means the difference of local storage, communication capabilities, CPU, memory, network connectivity and power of the devices in federated network. Also, each device could be unreliable and it’s common that they may drop out during the training process due to the energy or connectivity constrains. To deal with it, some client-selection methods have been proposed. And other works focus on improving the robustness of the system, or reduce the number of participants.
3. Statical Heterogeneity
Statical heterogeneity means that the data collected on each device is in a non-identically-distributed (non-IID) manner. Moreover, the number of data points could vary significantly. Both of them could do harm to the whole training process. For example, if we want to train a global model to classify the number from 0 to 9. As a result of non-IID, each device may has only few classes of number. In that case, after training locally, the local model could only identify few classes of number. And after weighted averaging of all the training results, the performance of the global model could be unexpectedly poor. To handle this problem, some works focus on reducing the non-IID degree by collecting a small global training set and then pre-train the global model before sending it to all devices. Other works focus on designing algorithms or combining federated learning to multi-task learning or mete-learning to reduce the impact of non-IID.
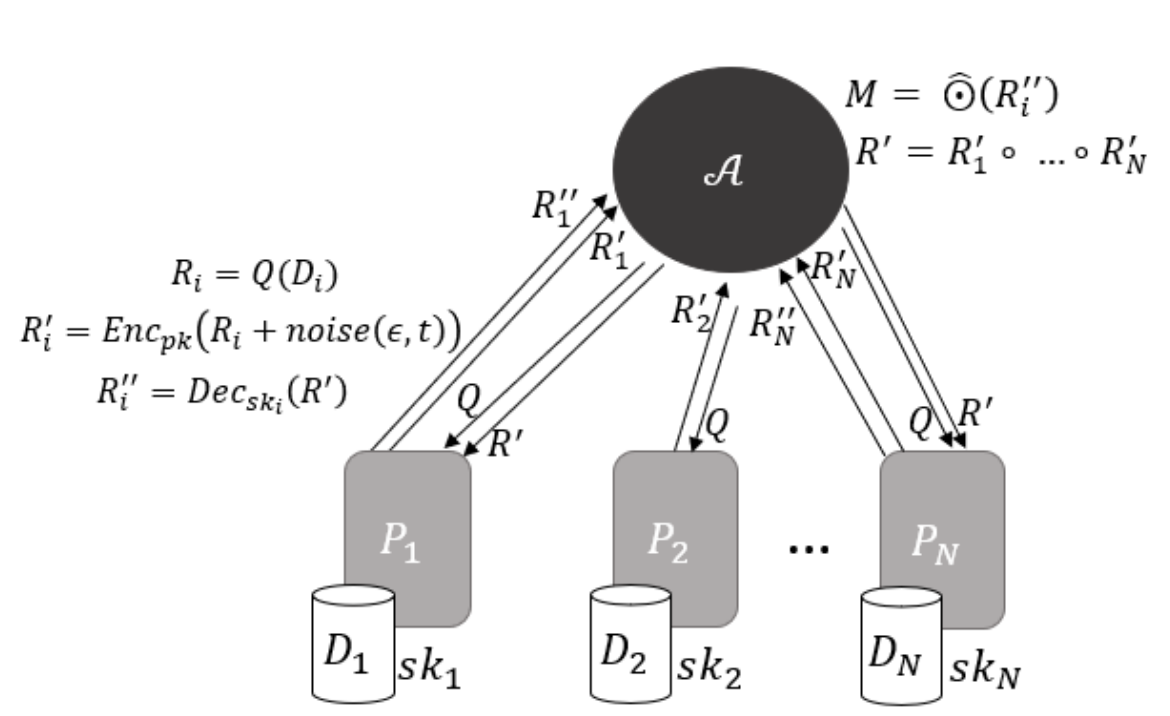
Finally, privacy is also a major concern in federated learning. Although uploading training results instead of raw data could protect the user privacy, it is still available to reveal sensitive information by analyzing the uploaded training results. Recent methods aim to enhance the privacy by using a secure multiparty computation or differential privacy technique. However these methods will do harm to the model performance. So it’s still a hot research topic in federated learning.
Thanks for your reading. If you are interested in federated learning, it’s good to find some top conference papers. And there are many popular federated learning frameworks such as TensorFlow Federated, it’s also a good choice to start with coding!
- Tweet
-

 2023/04/21
2023/04/21 2021/10/29
2021/10/29 2020/08/21
2020/08/21 2008/11/11
2008/11/11