開発
High Concurrency of database (MySQL)
Tang
For website developers, if the number of website visits is very large, then we need to consider related concurrent access issues. The concurrency problem is a headache for most programmers.
Synchronous responses & Asynchronous responses
Synchronous responses
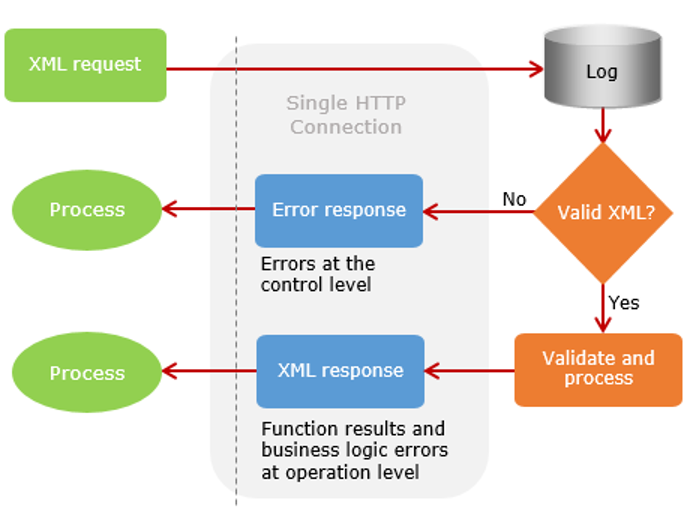
Synchronous responses are typically used when the client must wait to receive the response before processing continues on the client-side. A request is processed in real-time, and the gateway returns the response via the HTTP connection created by the client. If a validation error occurs, the error is returned synchronously.
Asynchronous responses
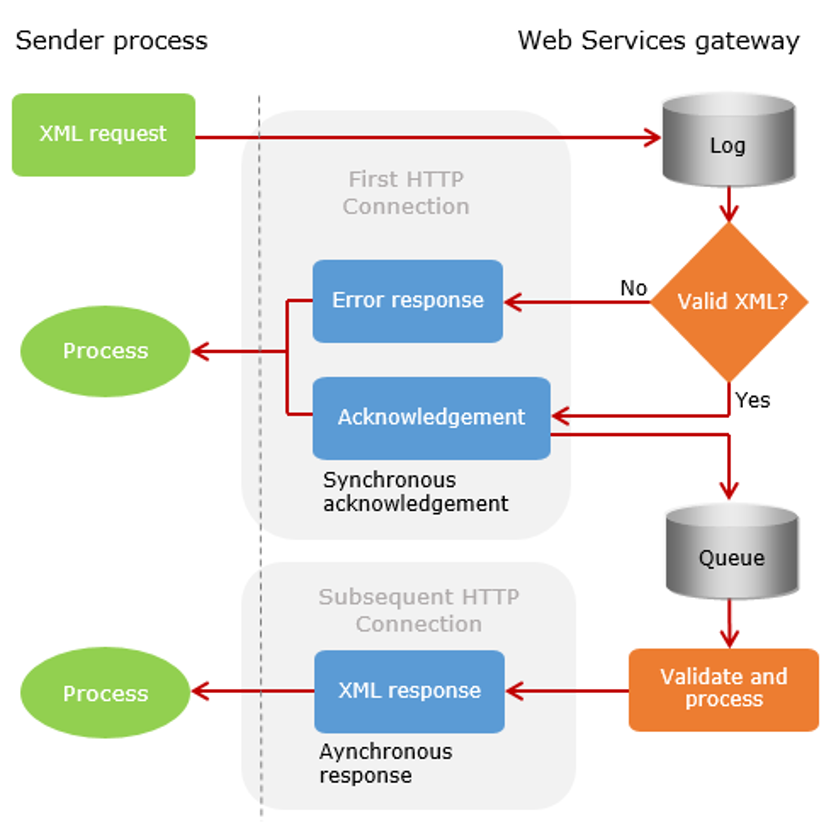
You can work with Sage Intacct to configure asynchronous processing if you do not want your client to wait for responses in the same HTTP connection. Asynchronous responses can be very useful when posting large requests that require significant processing time or when a response is not needed in the same HTTP connection.
[ reference: https://developer.intacct.com/web-services/sync-vs-async/ ]
To a certain extent, synchronization can be regarded as a single thread. This thread requests a method and waits for the method to reply to it, otherwise it will not execute down. To a certain extent, asynchronous can be regarded as multi-threaded. After requesting a method, it is ignored, and the other methods continue to be executed.
In Brief
Synchronization is one thing, one thing at a time. Asynchronous means doing one thing at the same time as not doing other things.
For example, eating and talking can only come one by one because there is only one mouth. But eating and listening to music are asynchronous because listening to music does not prevent us from eating.
Problems caused by high concurrency
Dirty Read
A dirty read (aka uncommitted dependency) occurs when a transaction is allowed to read data from a row that has been modified by another running transaction and not yet committed.
Dirty reads work similarly to non-repeatable reads; however, the second transaction would not need to be committed for the first query to return a different result. The only thing that may be prevented in the READ UNCOMMITTED isolation level is updates appearing out of order in the results; that is, earlier updates will always appear in a result set before later updates.
Non-repeatable read
A non-repeatable read occurs when, during the course of a transaction, a row is retrieved twice and the values within the row differ between reads.
Non-repeatable reads phenomenon may occur in a lock-based concurrency control method when read locks are not acquired when performing a SELECT, or when the acquired locks on affected rows are released as soon as the SELECT operation is performed. Under the multi-version concurrency control method, non-repeatable reads may occur when the requirement that a transaction effected by a commit conflict must rollback is relaxed.
[ reference: https://en.wikipedia.org/wiki/Isolation_(database_systems) ]
Solution–Pessimistic locks and Optimistic locks
Pessimistic locks
Pessimistic locks are very pessimistic, and always think that other threads will modify the situation. Lock before the operation. When other threads want to access data, they need to wait.
The realization of pessimistic locks depends on the locking mechanism provided by the database. In fact, only the locking mechanism provided by the database layer can truly guarantee the exclusivity of data access, otherwise, even if the locking mechanism is implemented in the system, there is no guarantee that the external system will not modify the data.
A typical pessimistic lock call that depends on the database
begin;
select quantity from products where id = 1 for update;
update products set quantity = 2 where id = 1;
commit;
This SQL statement locks all records in the user table that meet the search criteria (id = 1). Before this transaction is committed (the lock during the transaction is released when the transaction is committed), the outside world cannot modify these records.
It should be noted that updates should be put into the MySQL transaction, that is, begin and commit, otherwise it will not work.
Optimistic locks
Compared with pessimistic locks, Optimistic locks does not use the locking mechanism provided by the database when it is processed by the database. Generally, the version parameter is added to record the data version.
Optimistic locks believe that the probability of data competition between transactions is very small, so operate as directly as possible, and only lock when committing, without any locks or deadlocks.
select quantity from products where id = 1
update products set quantity = 2 where id = 1 and quantity = 3
Query the current inventory number of the inventory table first, and then determine whether the quantity of the data corresponding to the data table is the same as the first time when it is updated. If they are consistent, the data will be updated, otherwise, it is considered to be outdated data.
Introducing the version parameter, the optimistic lock will carry the version number every time the data modification operation is performed. Once the version number and the data version number are consistent, the modification operation can be performed and the version +1 operation can be performed, otherwise, the execution fails.
But there is also a problem with this implementation. If it is really in a high concurrency state, only one thread can be modified successfully, and there will be a large number of failures, which will make the user feel the failure.
Try to reduce the optimistic locks force to maximize throughput.
update products set quantity = quantity-1 where id = 1 and quantity-1> 0
Summary
Optimistic locks are not really locks. The efficiency of optimistic locks is high, but it is necessary to control the strength of the lock.
Pessimistic locks rely on database locks, and the efficiency of pessimistic locks is low.
- Tweet
-

 2024/01/05
2024/01/05 2023/08/18
2023/08/18 2023/07/14
2023/07/14 2023/05/12
2023/05/12 2023/04/21
2023/04/21 2023/04/19
2023/04/19 2023/03/24
2023/03/24 2022/12/23
2022/12/23